最近计网实验要求编程分析 tracert 命令所捕获的数据包,并将计算结果与命令行的显示结果比较。这就需要对 wireshark 捕获的数据包进行读取,网上 python 读取数据包的库很多,经过一一尝试,发现 scapy 库比较好用,抓、做、读一应俱全。Scapy官方使用说明 或 Scapy中文使用文档 。
注:这里最好使用python3,python2会出现读取时间戳精度不够的问题。
scapy使用方法如下,直接 import scapy 会出错。
1 import scapy.all as scapy
通过 rdpcap() 读取 pcap 文件,经过实验 pcapng 文件也没问题。
1 packets = scapy.rdpcap('tracert.pcap' )
直接输出 packets,输出的是所有包的类型信息。
1 <tracert.pcap: TCP:64 UDP:213 ICMP:8 Other:70>
可以使用 repr() 输出每一个包的详细信息。
1 2 for p in packets: print(repr(p))
1 2 3 <Ether dst=01:00:5e:7f:ff:fa src=48:02:2a:f8:9a:3e type=0x800 |<IP version=4 ihl=5 tos=0x0 len=202 id=3987 flags= frag=0 ttl=1 proto=udp chksum=0x106 src=172.16.12.128 dst=239.255.255.250 options=[] |<UDP sport=62198 dport=1900 len=182 chksum=0x54e4 |<Raw load='M-SEARCH * HTTP/1.1\r\nHOST: 239.255.255.250:1900\r\nMAN: "ssdp:discover"\r\nMX: 1\r\nST: urn:dial-multiscreen-org:service:dial:1\r\nUSER-AGENT: Google Chrome/69.0.3497.100 Windows\r\n\r\n' |>>>> <Ether dst=33:33:00:01:00:02 src=48:02:2a:f8:9c:39 type=0x86dd |<IPv6 version=6 tc=0 fl=0 plen=93 nh=UDP hlim=1 src=fe80::6c6e:5af0:6665:a46a dst=ff02::1:2 |<UDP sport=dhcpv6_client dport=dhcpv6_server len=93 chksum=0x5288 |<DHCP6_Solicit msgtype=SOLICIT trid=0xbc1287 |<DHCP6OptElapsedTime optcode=ELAPSED_TIME optlen=2 elapsedtime=1.00 sec |<DHCP6OptClientId optcode=CLIENTID optlen=14 duid=<DUID_LLT type=Link-layer address plus time hwtype=Ethernet (10Mb) timeval=Tue, 04 Dec 2012 07:29:23 +0000 (1354606163) lladdr=68:05:ca:0f:70:a1 |> |<DHCP6OptIA_NA optcode=IA_NA optlen=12 iaid=0x1848022a T1=0 T2=0 ianaopts=[] |<DHCP6OptClientFQDN optcode=OPTION_CLIENT_FQDN optlen=7 res=0 flags= fqdn='NL-11' |<DHCP6OptVendorClass optcode=VENDOR_CLASS optlen=14 enterprisenum=Microsoft vcdata=[<VENDOR_CLASS_DATA len=8 data='MSFT 5.0' |>] |<DHCP6OptOptReq optcode=ORO optlen=8 reqopts=[Domain Search List option, DNS Recursive Name Server Option, VENDOR_OPTS, OPTION_CLIENT_FQDN] |>>>>>>>>>> <Ether dst=01:00:5e:7f:ff:fa src=48:02:2a:f8:a5:c2 type=0x800 |<IP version=4 ihl=5 tos=0x0 len=202 id=10667 flags= frag=0 ttl=1 proto=udp chksum=0xe706 src=172.16.12.103 dst=239.255.255.250 options=[] |<UDP sport=60744 dport=1900 len=182 chksum=0x5aab |<Raw load='M-SEARCH * HTTP/1.1\r\nHOST: 239.255.255.250:1900\r\nMAN: "ssdp:discover"\r\nMX: 1\r\nST: urn:dial-multiscreen-org:service:dial:1\r\nUSER-AGENT: Google Chrome/69.0.3497.100 Windows\r\n\r\n' |>>>>
也可以使用 show() 以另一种形式输出每一个包的详细信息。
1 2 for p in packets: p.show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ###[ Ethernet ]### dst = 01:00:5e:7f:ff:fa src = 48:02:2a:f8:9a:3e type = 0x800 ###[ IP ]### version = 4 ihl = 5 tos = 0x0 len = 202 id = 3987 flags = frag = 0 ttl = 1 proto = udp chksum = 0x106 src = 172.16.12.128 dst = 239.255.255.250 \options \ ###[ UDP ]### sport = 62198 dport = 1900 len = 182 chksum = 0x54e4 ###[ Raw ]### load = 'M-SEARCH * HTTP/1.1\r\nHOST: 239.255.255.250:1900\r\nMAN: "ssdp:discover"\r\nMX: 1\r\nST: urn:dial-multiscreen-org:service:dial:1\r\nUSER-AGENT: Google Chrome/69.0.3497.100 Windows\r\n\r\n'
这里每个包 p 的结构如下:
物理层 --> 网络层 --> 传输层 --> 应用层
每一层的数据都可以根据相应层的协议名获取,然后再通过字段名获取具体层具体字段的信息。判断是否包含某一层,用 haslayer(),或者直接用 if 'x' in p 判断。
1 2 3 4 5 6 7 8 9 10 11 12 13 for p in packets: if p.haslayer('Ether' ): print(p['Ether' ].name) print('src: %s' % p['Ether' ].src) print('dst: %s' % p['Ether' ].dst) if p.haslayer('IP' ): print(p['IP' ].name) print('src_ip: %s' % p['IP' ].src) print('dst_ip: %s' % p['IP' ].dst) if 'TCP' in p: print(p['TCP' ].name) print('sport: %s' % p['TCP' ].sport) print('dport: %s' % p['TCP' ].dport)
1 2 3 4 5 6 7 8 9 Ethernet src: 48:02:2a:f8:a5:c2 dst: 01:00:5e:7f:ff:fa IP src_ip: 172.16.12.117 dst_ip: 172.16.15.255 TCP sport: 443 dport: 1278
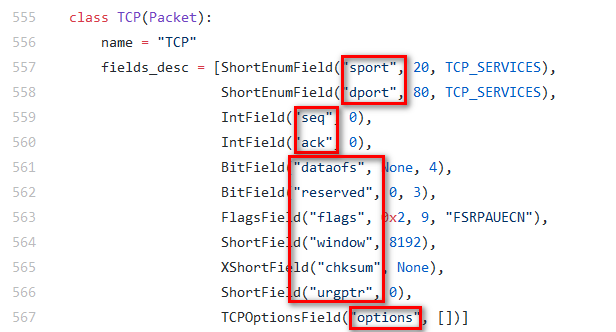
基本的字段都能通过 repr() 看到,如果还想看别的字段,可以参考源码:https://github.com/secdev/scapy/tree/master/scapy/layers l2.py,ip、tcp 等在 inet.py 中,例如 tcp 的一些字段名称在这:
这里有个比较重要的属性 payload,可以获取上一层协议的数据。
1 2 3 4 5 for p in packets: print(repr(p)) print(p.name) print(p.payload.name) print(p.payload.payload.name)
1 2 3 4 <Ether dst=01:00:5e:7f:ff:fa src=48:02:2a:f8:a5:c2 type=0x800 |<IP version=4 ihl=5 tos=0x0 len=202 id=10667 flags= frag=0 ttl=1 proto=udp chksum=0xe706 src=172.16.12.103 dst=239.255.255.250 options=[] |<UDP sport=60744 dport=1900 len=182 chksum=0x5aab |<Raw load='M-SEARCH * HTTP/1.1\r\nHOST: 239.255.255.250:1900\r\nMAN: "ssdp:discover"\r\nMX: 1\r\nST: urn:dial-multiscreen-org:service:dial:1\r\nUSER-AGENT: Google Chrome/69.0.3497.100 Windows\r\n\r\n' |>>>> Ethernet IP UDP
payload.original 可以获取某一层的原始负载。
1 2 3 for p in packets: if p.haslayer('TCP' ): print(p['TCP' ].payload.original)
1 b'\x17\x03\x03\x00)\x1e\xa7\xfc\xfc\x86h1#\xefX\xa8\x9a#|\x86\x8ajn\x89\xf7\xe9zI\t\x1bU\x92\xdc\x1f\xc4\x9ec\xa3\x80\xee\x90\xd1b\x1e\x7f&'
获取时间戳:
1 2 for p in packages: print p.time
1 2 3 1541400330.983909 1541400331.689689 1541400332.689724
输出是 unix 时间。
查看 scapy/layers 就会发现,scapy 不支持 HTTP 协议,分析包含 HTTP 协议的报文,结果都被解析为 RAW 协议。
1 2 ###[ Raw ]### load = 'POST /eapi/pl/count HTTP/1.1\r\nHost: music.163.com\r\nConnection: keep-alive\r\nContent-Length: 1095\r\nAccept: */*\r\nContent-Type: application/x-www-form-urlencoded\r\nOrigin: orpheus://orpheus\r\nUser-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.157 Safari/537.36\r\nAccept-Encoding: gzip,deflate\r\nAccept-Language: en-us,en;q=0.8\r\nCookie: os=pc; deviceId=C63458DF49DAC6B15D327354B64868F78B71284D80FA5B348515; osver=Microsoft-Windows-10--build-16299-64bit; appver=2.5.0.196623; channel=netease; MUSIC_A=a1bb41f19068d8848ee72d56d618a3aeeb806be238e75ff9ebb04e6d95ae4bc61837dd27894f529f93e040c80614859f3f50f5aa87a636060104b82f5f97c42dd83eb46aa719054edb75e26080174d3953a501eebaa6be05e481f3d2803b224bc3061cd18d77b7a0; mode=T57-S5; MUSIC_U=6aeb8c54ed91d900261247e85377f8eb9f1597704e8458080f82300879cba67a49732e6193abac96a90359dee83d1a9faf9e62a8590fd08a; __remember_me=true; __csrf=e3143fcac555f0fa618512525f0f76ad\r\n\r\n'
因此,有人对 scapy 进行了补充,项目地址:https://github.com/invernizzi/scapy-http pip 安装 scapy-http,导入该库即可解析 HTTP 协议
1 2 import scapy.all as scapyimport scapy_http.http
可以看到 HTTP 正常解析。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 ###[ HTTP ]### ###[ HTTP Request ]### Method = 'POST' Path = '/eapi/pl/count' Http-Version= 'HTTP/1.1' Host = 'music.163.com' User-Agent= 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.157 Safari/537.36' Accept = '*/*' Accept-Language= 'en-us,en;q=0.8' Accept-Encoding= 'gzip,deflate' Accept-Charset= None Referer = None Authorization= None Expect = None From = None If-Match = None If-Modified-Since= None If-None-Match= None If-Range = None If-Unmodified-Since= None Max-Forwards= None Proxy-Authorization= None Range = None TE = None Cache-Control= None Connection= 'keep-alive' Date = None Pragma = None Trailer = None Transfer-Encoding= None Upgrade = None Via = None Warning = None Keep-Alive= None Allow = None Content-Encoding= None Content-Language= None Content-Length= '1095' Content-Location= None Content-MD5= None Content-Range= None Content-Type= 'application/x-www-form-urlencoded' Expires = None Last-Modified= None Cookie = 'os=pc; deviceId=C63458DF49DAC6B15D327354B64868F78B71284D80FA5B348515; osver=Microsoft-Windows-10--build-16299-64bit; appver=2.5.0.196623; channel=netease; MUSIC_A=a1bb41f19068d8848ee72d56d618a3aeeb806be238e75ff9ebb04e6d95ae4bc61837dd27894f529f93e040c80614859f3f50f5aa87a636060104b82f5f97c42dd83eb46aa719054edb75e26080174d3953a501eebaa6be05e481f3d2803b224bc3061cd18d77b7a0; mode=T57-S5; MUSIC_U=6aeb8c54ed91d900261247e85377f8eb9f1597704e8458080f82300879cba67a49732e6193abac96a90359dee83d1a9faf9e62a8590fd08a; __remember_me=true; __csrf=e3143fcac555f0fa618512525f0f76ad' Headers = 'Host: music.163.com\r\nConnection: keep-alive\r\nContent-Length: 1095\r\nAccept: */*\r\nContent-Type: application/x-www-form-urlencoded\r\nOrigin: orpheus://orpheus\r\nUser-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.157 Safari/537.36\r\nAccept-Encoding: gzip,deflate\r\nAccept-Language: en-us,en;q=0.8\r\nCookie: os=pc; deviceId=C63458DF49DAC6B15D327354B64868F78B71284D80FA5B348515; osver=Microsoft-Windows-10--build-16299-64bit; appver=2.5.0.196623; channel=netease; MUSIC_A=a1bb41f19068d8848ee72d56d618a3aeeb806be238e75ff9ebb04e6d95ae4bc61837dd27894f529f93e040c80614859f3f50f5aa87a636060104b82f5f97c42dd83eb46aa719054edb75e26080174d3953a501eebaa6be05e481f3d2803b224bc3061cd18d77b7a0; mode=T57-S5; MUSIC_U=6aeb8c54ed91d900261247e85377f8eb9f1597704e8458080f82300879cba67a49732e6193abac96a90359dee83d1a9faf9e62a8590fd08a; __remember_me=true; __csrf=e3143fcac555f0fa618512525f0f76ad' Additional-Headers= 'Origin: orpheus://orpheus\r\n'
然后可以查看 HTTP 中一些字段的信息
1 2 3 4 5 6 for p in packets: if p.haslayer("HTTPRequest" ): print("host: %s" % p["HTTPRequest" ].Host) print("url: %s" % p["HTTPRequest" ].Path) print("http_fields:\n%s" % p["HTTPRequest" ].fields) print("http_payload:\n%s" % p["HTTPRequest" ].payload.fields)
1 2 3 4 5 6 host: b'ocsp.comodoca.com' url: b'/' http_fields: {'Headers': b'Host: ocsp.comodoca.com\r\nUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\nAccept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2\r\nAccept-Encoding: gzip, deflate\r\nContent-Type: application/ocsp-request\r\nContent-Length: 83\r\nConnection: keep-alive', 'Host': b'ocsp.comodoca.com', 'User-Agent': b'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0', 'Accept': b'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': b'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2', 'Accept-Encoding': b'gzip, deflate', 'Connection': b'keep-alive', 'Content-Length': b'83', 'Content-Type': b'application/ocsp-request', 'Method': b'POST', 'Path': b'/', 'Http-Version': b'HTTP/1.1'} http_payload: {'load': b'0Q0O0M0K0I0\t\x06\x05+\x0e\x03\x02\x1a\x05\x00\x04\x14z\xe1>\xe8\xa0\xc4*,\xb4(\xcb\xe7\xa6\x05F\x19@\xe2\xa1\xe9\x04\x14\x90\xafj:\x94Z\x0b\xd8\x90\xea\x12Vs\xdfC\xb4:(\xda\xe7\x02\x10j\xef\xbd\xdc\xaf\x99\xa4\x0c\xf3\xa3\xe2\x1b\xa9\xdeC\t'}
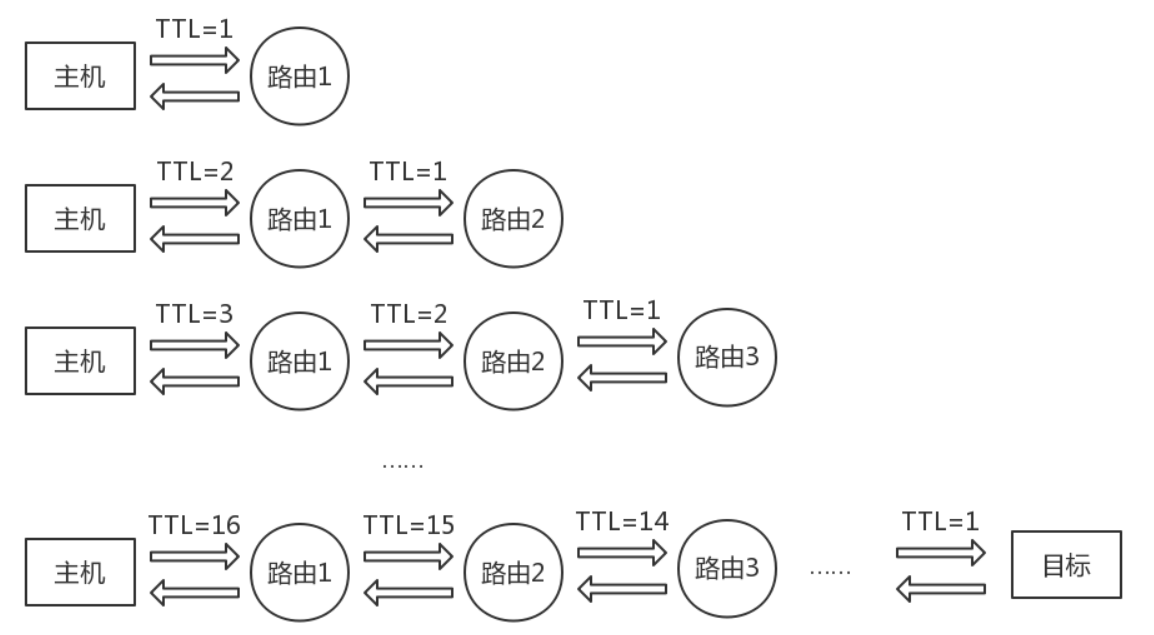
tracert 通过向目标发送不同 TTL 值的 ICMP 包,每个路由器在转发数据包之前将数据包上的 TTL 递减 1。数据包上的 TTL 减为 0 时,路由器应该将“ICMP 已超时”的消息发回本机。
在 cmd 中输入命令,并用 wireshark 抓包:
1 $ tracert -d www.baidu.com
其中 -d 是不将地址解析成主机名,节省不必要的时间。
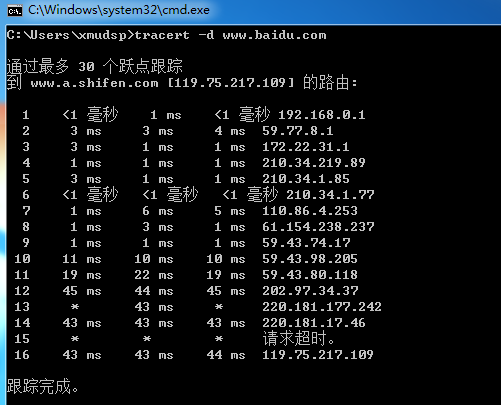
发现经过 16 个路由到达了目标百度的 IP 地址:119.75.217.109。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import scapy.all as scapydef parse (pcap_path, sip) : packets = scapy.rdpcap(pcap_path) data = [] last_src = '' for p in packets: if p.haslayer('ICMP' ): if p['IP' ].src != sip and p['IP' ].dst != sip: continue group = [] if p['IP' ].src == last_src: data.append([]) group.append(p.time) group.append(p['IP' ].src) group.append(p['IP' ].dst) group.append(p['IP' ].ttl) last_src = p['IP' ].src data.append(group) return data def analyse (data, dip) : print('通过最多30个跃点跟踪' ) print('到[%s]的路由' % dip) for i in range(0 , len(data), 6 ): time = [0 , 0 , 0 ] ip = '请求超时' for j in range(3 ): if data[i+2 *j+1 ]: time[j] = str(round((data[i+2 *j+1 ][0 ] - data[i+2 *j][0 ]) * 1000 , 1 )) + 'ms' ip = data[i+2 *j+1 ][1 ] else : time[j] = '*' print('%2d %7s %7s %7s %-15s' % (int(i / 6 ) + 1 , time[0 ], time[1 ], time[2 ], ip)) print("跟踪完成" ) def main () : data = parse('tracert.pcap' , '本机IP地址' ) analyse(data, '目标IP地址' ) if __name__ == '__main__' : main()
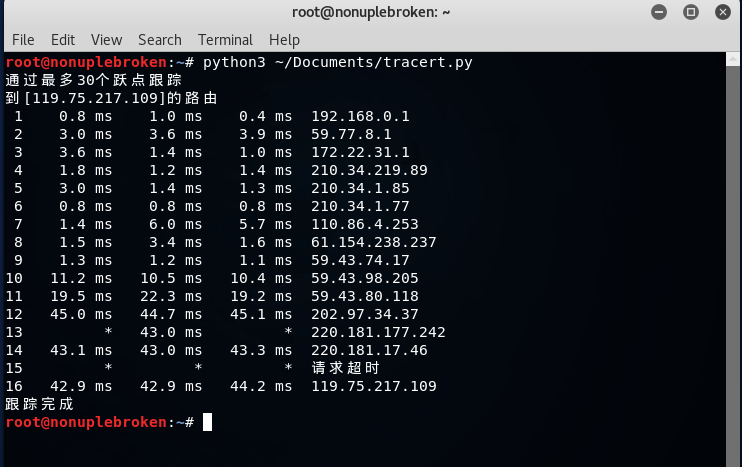
得到结果:
这里时间差采用了一位小数的毫秒,比 tracert 命令的结果更准确,不会出现“<1毫秒”。